
Figure 0: the virtual loudspeaker method applied to ambisonic rendering.
In practice, some steps of this scheme can be merged to reduce computation cost.
- Sound Illustrations
of First and Higher Order Ambisonics plus Optimised Decoding Solutions
- Audible Proofs of
Localization Theories
- All that accompanied
by comments, figures, and movies
Preamble
Ideal,
centred listening position with static sound images
Evaluating
sound image robustness with off-centred listening positions - Circular
trajectories
(...Probably
the more enjoyable demos)
Other (future?) interesting experiments
You
can leave me your feedback!
First published: 2000/12/20 - Last modified: 2001/01/14
Restrictions of these page
These sound demonstrations deal only with 2D (horizontal) regular loudspeaker
configurations! Perhaps I'll extend them to 3D ambisonic rendering in the
future!?
This page focusses on perceptual aspects. Almost all comments
were presented (in french) in my thesis but I haven't included some
of the basic definitions (eg of the velocity and energy vectors):
please
refer to usual ambisonic references (eg Gerzon's papers), or
to
my documents (thesis
or powerpoint presentation)
for
further details and mathematical/physical demonstrations. Moreover,
this
is not the place for explaining how the decoding is defined: please
refer to my documents (thesis
or powerpoint presentation)
or to future web pages (in english) for that! Nevertheless, you can visualize
the different kinds of decoding here.
Finally, explicit biblio references in this page are still rare at
present. Please excuse me and refer to my thesis and its bibliography.
General presentation
These sound examples should be considered as a complement to the objective
evaluations presented in the 4th chapter of my
thesis, or more briefly on the slide entitled "Evaluation
et comparison des décodages" in my
powerpoint presentation.
All the sound illustrations presented below are processed by a binaural
simulation of ambisonic rendering over loudspeakers, the listening
position being controlled with regard to the virtual loudspeaker configuration.
Thus, these sound files have
to be listened over
headphones. They are either WAV or MP3 files.
The process (the virtual rendering)
This is a "light version" of the now well known "virtual loudspeaker"
principle: one pair of filters (HRTF: Head Related Tranfer Functions) is
associated to each virtual loudspeakers as a function of its direction
(from the listener viewpoint), thus the signal which should be delivered
by the loudspeaker is filtered to yield its contribution to the left and
right ear signals (see Figure 0). The filters used
are "dry" HRTF, they have been measured by K.Martin & B.Gardner on
a KEMAR dummy head and have been made available
for years by their authors on the MIT Web Site. Thanks to them!
For an experimental purpose, I have also considered off-centre listening
positions, which imply directional and amplitude distorsions as well as
time delays between the waves virtually impinging the head and coming from
the (virtual) loudspeakers. Nevertheless, we ignore the near field effect
of the loudspeakers, which mostly affects the (very) low frequency field
(by
the way, the near field effect of the loudspeaker used for the HRTF measurements
has not been compensated).
Here, we consider the situation of a single virtual sound image,
ambisonically encoded/decoded, then rendered by the virtual loudspeakers.
Preliminary remarks
Of course, these simulations cannot replace a true listening
experience with real loudspeakers in a real room. Many aspects differenciate
the virtual listening experience from the real one:
- The HRTF are not measured on your own head and (a priori)
don't really yield natural spectral cues for you.
- There's no room effect associated to the virtual loudspeakers.
- You're head is supposed to be fixed, there is no correction of the
sound field at your ears when you rotate your head, thus the dynamic localisation
mechanisms cannot be satisfied.
Because of these limitations, the virtual listening experience suffers
from well known artefacts, such as the lack of externalisation (the
sound is heard inside your head), front-back reversals and, finally, localization
ambiguities.
That's why we can evaluate the rendering only by a comparison with
a reference. This reference is produced as a "direct" binaural simulation
of the original virtual sound source: this would be the effect of a single
virtual loudspeaker in the expected direction, instead of the effect of
the whole set of virtual loudspeakers used for the ambisonic rendering.
Here are given auditory illustrations as a complement to the results of the section 4.1 of my thesis (see also the slide entitled "Evaluation et comparaison des décodages" of my powerpoint presentation.)
This figure presents a few notations used later:

Figure 0-bis.
Notations associated to an arbitrary loudspeaker configuration
and the reproduction of a virtual sound source.
The length of each large arrow is proportional to the
associated gain Gi.
In the following, the notation usomething
will designate an unitary vector used to describe the incidence direction
of something.
Are discussed:
Spectral
Reconstruction
Low
Frequency Lateralisation Effect - Velocity Vector Theory (or Makita's Theory,
referred by Gerzon)
Higher
Frequency Lateralisation Effect - Energy Vector Theory (introduced by Gerzon)
The
Problem of the Spectral Balance - Discussion about the Amplitude/Energy
Preservation Criteria
Spectral
Reconstruction
Recall
One major property of ambisonic rendering is the local, centred reconstruction
of the acoustic field, provided when a so-called "basic" decoding
is applied. The area width of the valid reconstruction is proportional
to the wave length, and it increases as higher orders are considered. This
is illustrated here: reconstruction of a monochromatic plane wave (reference
on the right), order M=1 to 5 from the left to the right, 2D reconstruction
at top, 3D reconstruction at bottom.
(To be exact, these represent the Mth order truncatures
of the cylindrical(2D)/spherical(3D) harmonic decomposition of the plane
wave. For a given order, this is equivalent to an ambisonic rendering using
an infinite number of loudspeakers. The extent of the reconstruction area
is very similar when using a finite number of loudspeakers).


We observe that the reconstruction quality depends on the virtual source angle and also on the loudspeaker angles: it is generally better when the virtual source direction is the same as one loudspeaker.
Auditory experiment
Now, how does it sounds like? Here's a short sound sequence
(Tracy Chapman) with a rather rich spectral content. The virtual source
position is fixed at -90 degrees (right side). A "basic" decoding is applied
to the full bandwidth. On the second line, you can hear the difference
(or "reconstruction error") between the reference and the virtual ambisonic
rendering.
| Reference | 1st order | 2nd order | 3rd order | 4th order | 5th order |
| Tracy90° direct binaural | Tracy90° o1 basic | Tracy90° o2 basic | Tracy90° o3 basic | Tracy90° o4 basic | Tracy90° o5 basic |
| Difference | Tracy90° o1 basic | Tracy90° o2 basic | Tracy90° o3 basic | Tracy90° o4 basic | Tracy90° o5 basic |
Remarks and advices
It can be quite difficult to hear noticeable differences between some
versions (of the first line) or to determine a "preference" among them,
since even the reference example doesn't itself yield a very appreciable
"spatial enjoyment" (it's only a monophonic source spatialised
without any room effect) and there's no signal degradation (in
the usual sense of quantisation noise). Better subjective appreciations
should be provided with the a complex sound environment example, and in
a "real listening situation" regarding the question of the stability. In
the present situation, we must be aware of two objective facts (see
Figure
2): (1) the reconstruction quality changes
with the virtual source azimuth for a given virtual loudspeaker configuration,
and (2) even above the frequency limit (black line),
the spectral cues are more or less preserved.
If you listen the "reconstruction error" (second line of the table
above), you'll hear a low-cut filter effect with an increasing cut-off
frequency as the order increases (though some inversions
could at other azimuths, see figure 2).
It's more convenient to listen the different versions one just after
the other. As soon as you have downloaded the sound files, you can play
them in a "play-list" (e.g. with WinAmp or another player...),
for instance.
Low
Frequency Lateralisation Effect - Velocity Vector Theory (or Makita's Theory
as referred by Gerzon)
Recall
We have just seen that thanks to the "basic decoding" and for a centred
head, the acoustic field round the head and at the ears conforms to the
original/encoded event in a low frequency domain. As is evident, the localisation
effect is thus preserved regarding the low frequency ITD (seen as the interaural
phase delay ) in a low frequency domain which extends while the system
order increases.

But what if another decoding style is chosen? Considering the experience
of a plane wave again, the ambisonic rendering keeps this interesting property:
the apparent direction and speed of the local propagation remains
constant with frequency (this, is because the waves coming
from the loudspeakers only differ by an amplitude ratio and arrive synchroneously
at the central point). The direction of the synthetic wave front
(given by the velocity vector V,
defined as the mean of the loudspeaker directions weighted by the associated
amplitude: V=SGiui/SGi) is the same as the original event, and the
apparent speed cV is
related to the modulus rV of the velocity vector V :
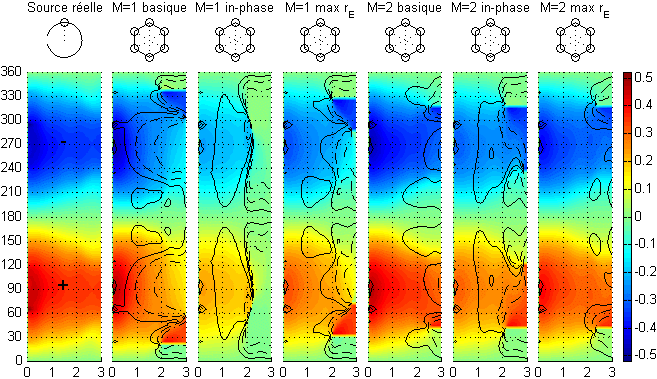
Figure 4
Interaural phase delay for 1st and 2nd order
ambisonic rendering.
Same legend as above, excepted that the black line defines
the low frequency limit for the prediction
(cont. lines for a
0.02ms error, dashed lines for a 0.05ms error, dashed-dotted lines for a 0.1ms
error).
See
Table 3 for the corresponding values of
Auditory experiment
The
different decoding solutions give various values of rV , which are constant
for any azimuth when the loudspeaker configuration is regular (see Table 3 below). They are all less or equal
to unity. rV<1
means that the LF ITD, thus the lateralisation effect is less than the expected
one (see
The following table (Table 2) let you hear
this effect with a virtual source at -90° (right) in the horizontal plane. The
original sound is a low frequency noise (cut-frequency at 780Hz). The predicted
localisation effect is given in the next table (
Good headphones and a high attention are required to
appreciate the lateral changes for high orders...
Theses .wav files are
short and have been resampled at 6 kHz. The shortest are only 10 and 29 Ko long.
The others (concatenations) are 66 Ko and 104 Ko long.
| (Virtual source at -90°) Reference |
1st order | 2nd order | 3rd order | 4th order | 5th order | Concatenation (ref[1|2|3|4|5) |
| Basic decoding | LF
noise_o1_basic Ref +_o1_basic |
LF
noise o2 basic Ref +_o2 basic |
LF
noise o3 basic Ref +_o3 basic |
LF noise o4
basic Ref +_o4 basic |
LF noise o5
basic Ref +_o5 basic |
Ref + basic(1-5) |
| Max rE decoding | LF
noise o1 max rE Ref +_o1_max rE |
LF
noise o2 max rE Ref +_o2 max rE |
LF
noise o3 max rE Ref +_o3 max rE |
LF noise o4 max
rE Ref +_o4 max rE |
LF noise o5 max
rE Ref +_o5 max rE |
Ref + |
| In-phase decoding | LF
noise o1 in-phase Ref +_o1_in-phase |
LF
noise o2 in-phase Ref +_o2 in-phase |
LF
noise o3 in-phase Ref +_o3 in-phase |
LF noise o4
in-phase Ref +_o4 in-phase |
LF noise o5
in-phase Ref +_o5 in-phase |
Ref + in-phase(1-5) |
| Concatenation (ref|basic|max rE|in-phase) |
Ref + o1 | Ref + o2 | Ref + o3 | Ref + o4 | Ref + o5 | Nothing else here |
Comparison with the prediction and
interpretation
Here is a table with the corresponding rV for a regular, 2D
(horizontal) loudspeaker layout. The localisation effect is predicted for a
given virtual source at -90° (right) in the horizontal
plane, and assuming the listener's head is static. q=-90°+arccos(rV) gives the value of the predicted azimuth,
assuming that the source is in the horizontal, front half plane. d=arccos(rV) gives the angle of the equivalent ambiguity
cone (ie the angle between a plausible direction and
the interaural axis).
| (Virtual source at -90°) | 1st order | 2nd order | 3rd order | 4th order | 5th order |
| Basic decoding | rV=1 (q=-90°,d=0°) |
rV=1 (q=-90°,d=0°) |
rV=1 (q=-90°,d=0°) |
rV=1 (q=-90°,d=0°) |
rV=1 (q=-90°,d=0°) |
| Max rE decoding | rV=0.707 (q=-45°,d=0°) or (q=-90°,d=45°) |
rV=0.866 (q=-60°,d=0°) or (q=-90°,d=30°) |
rV=0.924 (q=-67.5°,d=0°) or (q=-90°,d=22.5°) |
rV=0.951 (q=-72°,d=0°) or (q=-90°,d=18°) |
rV=0.966 (q=-75°,d=0°) or (q=-90°,d=15°) |
| In-phase decoding | rV=0.5 (q=-30°,d=0°) or (q=-90°,d=60°) |
rV=0.667 (q=-41.8°,d=0°) or (q=-90°,d=48.2°) |
rV=0.75 (q=-48.6°,d=0°) or (q=-90°,d=41.4°) |
rV=0.8 (q=-53.1°,d=0°) or (q=-90°,d=36.9°) |
rV=0.833 (q=-56.4°,d=0°) or (q=-90°,d=34.6°) |
With a rendering over loudspeakers, d can be also interpreted as an elevation angle when the listener rotates his/her head
(yaw rotation: the
interaural axis remains in the horizontal plane). But in this case, the
perceived azimuth is the same as the virtual source. This detection is explained
by considering the ITD and its variation together, and by comparison with the
perception of a natural, elevated sound source: see this movie (where rV=cosd), also included in my powerpoint
presentation.
When any head rotation is allowed, the listener can
detect the direction of the synthetic wave front (thus the direction of the
virtual source: azimuth and elevation) completely, but if rV<1, he/she will
never experience such great variations of ITD as he/she would with a natural
sound source (ie a "true" plane wave). Therefore, rV<1 can be
interpreted as a lack of precision of the sound
localisation.
Having a good lateralisation effect is
important not only for the localisation, but also for preserving good spatial impressions (S.I.) such as
envelopement, when we consider the rendering of a complex sound field (with
lateral reflections and reverberation). In the low frequency domain, S.I. are
related to the fluctuations of ITD (phase delay) (Cf Griesinger).
Conclusion
Unlike the
"basic" decoding, the "max rE" and especially "in-phase" decoding are under-optimal for the low
frequency rendering and for a centred listening
position. Nevertheless, they get closer to the "basic" decoding as the order M increases.
Higher Frequency Lateralisation Effect - Energy Vector Theory (introduced by Gerzon)
Recall:
The goal of
decoding is to provide an accurate localisation effect and to preserve spatial
impressions as well as possible. As a sub-goal, it should be able to yield as
well as possible the perceptual effect of a plane wave, seen as an elementary
acoustic event. We've seen that this can be easily achieved in a low frequency
domain.
In the higher frequency domain, where acoustic
reconstruction can no longer be achieved at ears, the directional detection of
an acoustic event relies on a kind of perceptual artefact, since the
reconstructed signals don't correspond to the experience of a true plane wave.
Gerzon (see the bibliography in my thesis) introduced a mathematical criterion
to characterise the localisation in this domain: the energy vector E (E=SGi2ui/SGi2: the mean of
the loudspeaker directions ui weighted by the
associated energy Gi2), which modulus rE (always<=1) should be maximised for a better
localisation accuracy. One can give an intuitive interpretation to this
criterion: the closer rE is to 1, the more the major energy
contributions are confined in a small angular sector in the direction uE of E, and therefore it seems clear that the sound
image is more precise and more robust. Though Gerzon had embedded this concept
in a strong theoretical context ("General
Metatheory of Auditory Localisation", 92nd Conv. AES, 1992), it has
remained difficult to explicit the relation between this vector and the
perceptive effects. I've tried to give some answers to this question, focussing
on lateralisation mechanisms and using the ILD (Interaural Level Difference) and
the high frequency ITD (detected as an interaural group delay) for that.
Characterising the lateralisation effect through the energy
vector E and its modulus
rE
Like the
velocity vector, the energy vector concept have first of all to be used when the contributing waves differ only in amplitude and arrive
synchroneously at the listening point (as
in Figures 5 and 6) (though it can be still pertinent in extended
conditions, see later), considering the
reproduction of an elementary acoustic event (seen as a plane wave). Hence, this
concerns ambisonics as well as two- or multi-channel DI-sterophony.
The
demonstrations I propose next are based on: (1) the detection of the interaural group delay (HF
ITD), which is supposed to apply with transients or modulated signals; (2) the consideration of ILD, which becomes
significant above 1.5 or 2 kHz.

The auditory experience
The spatialised sound is a noise burst (low frequency cut
at 1.2kHz) with a 10ms bell shaped amplitude envelope.
Caution: it's an especially hard listening
test! (And it is not a very pleasant sound!) A very (very) high
attention is required to hear differences most of time. Close your eyes if this
helps you.
Training sound file
I suggest you to experience this situation, so that you get
used to perceive the lateral displacement of the noise burst: the burst is
repeated 19 times and moves from right (-90°) to front (0°) in steps of 5° (direct binaural simulation of the single sound
source). Listen to it (262Ko, fs=32kHz, duration about 2s). If you can
(using eg CoolEdit), train yourself on the first
part of the sound file (where the directional discrimination is less evident).
The virtual source is located at -90° (right hand). Like
the simulations of Tables 1 and 2, the virtual
loudspeaker configurations are those represented Figure 2. For an
efficient comparison, you can play the "concatenated" versions directly (last
column and line).
| (Virtual source at -90°) Reference (2Ko) |
1st order | 2nd order | 3rd order | 4th order | 5th order | Concatenation (ref[1|2|3|4|5) (321 Ko) |
| Basic decoding (2Ko / 53Ko) |
o1_basic
Ref +_o1_basic |
o2
basic Ref +_o2 basic |
o3
basic Ref +_o3 basic |
o4
basic Ref +_o4 basic |
o5
basic Ref +_o5 basic |
Ref + basic(1-5) |
| Max rE
decoding (2Ko / 53Ko) |
o1 max
rE Ref +_o1_max rE |
o2 max
rE Ref +_o2 max rE |
o3 max
rE Ref +_o3 max rE |
o4
max rE Ref +_o4 max rE |
o5
max rE Ref +_o5 max rE |
Ref
+ |
| In-phase decoding (2Ko / 53Ko) |
o1
in-phase Ref +_o1_in-phase |
o2
in-phase Ref +_o2 in-phase |
o3
in-phase Ref +_o3 in-phase |
o4
in-phase Ref +_o4 in-phase |
o5
in-phase Ref +_o5 in-phase |
Ref + in-phase(1-5) |
| Concatenation (193Ko) (ref|basic|max rE|in-phase) (basic|in-phase|max rE|ref) |
Ref|o1b|
o1m|o1i o1b|o1i| o1m|ref |
Ref|o2b|
o2m|o2i o2b|o2i| o2m|ref |
Ref|o3b|
o3m|o3i o3b|o3i| o3m|ref |
Ref|o4b|
o4m|o4i o4b|o4i| o4m|ref |
Ref|o5b|
o5m|o5i o5b|o5i| o5m|ref |
Nothing else here |
| Direct binaural sim. | 1st order | 2nd order | 3rd order | 4th order | 5th order |
| Basic decoding | rE=0.667 (q>=-41.8°,d=0°) or (q=-90°,d>=48.2°) |
rE=0.8 (q>=-53.1°,d=0°) or (q=-90°,d>=36.9°) |
rE=0.857 (q>=-59°,d=0°) or (q=-90°,d>=31°) |
rE=0.889 (q>=-62.7°,d=0°) or (q=-90°,d>=27.3°) |
rE=0.909 (q>=-65.4°,d=0°) or (q=-90°,d>=24.6°) |
| Max rE decoding | rE=0.707 (q>=-45°,d=0°) or (q=-90°,d>=45°) |
rE=0.866 (q>=-60°,d=0°) or (q=-90°,d>=30°) |
rE=0.924 (q>=-67.5°,d=0°) or (q=-90°,d>=22.5°) |
rE=0.951 (q>=-72°,d=0°) or (q=-90°,d>=18°) |
rE=0.966 (q>=-75°,d=0°) or (q=-90°,d>=15°) |
| In-phase decoding | rE=0.667 (q>=-41.8°,d=0°) or (q=-90°,d>=48.2°) |
rE=0.8 (q>=-53.1°,d=0°) or (q=-90°,d>=36.9°) |
rE=0.857 (q>=-59°,d=0°) or (q=-90°,d>=31°) |
rE=0.889 ((q>=-62.7°,d=0°) or (q=-90°,d>=27.3°) |
rE=0.909 (q>=-65.4°,d=0°) or (q=-90°,d>=24.6°) |
You see that basic decoding and in-phase decoding give the same values of rE. But maybe you have found that the in-phase decoding gives a better lateralisation effect. This is clearly indicated by quantitative evaluations of ITD and ILD. Although rE indicates a same "energy concentration rate" for both decodings, the energy associated to the loudspeakers is more continuously distributed towards the virtual source direction with the in-phase decoding.
The interpretation of rE as a function of the listening constraints
(static, yaw rotation or any rotation allowed) is very similar to what what has
been described with rV in the low frequency domain (see above). Nevertheless,
special comments should be added. Unlike what happens in the LF domain, the ear
signals are "smeared", compared to what would occur with a single plane wave
experience, and the estimated cues (ITD and ILD) are much less
regular/continuous with regard to the azimuth.
As a
consequence:
(1) The lateralisation quality is generally less
good than the predicted values (given in the table).
(2) Although
there is a global improvement of lateralisation
while increasing order and choosing the supposed optimal decoding, it is not
necessarily perceived in the same way considering a fixed azimuth.
(3) Besides ITD
and ILD, there's another important aspect that can change the perceived
localization quality: the spectral coloration/balance (see also a bit later).
This can make the appreciation of the lateralisation itself difficult.
Conclusion
The "max rE" decoding is optimal
in the HF domain for a centred head, whereas the "basic" and the "in-phase" ones
are under-optimal. In the present test conditions, this is more perceptible with
1st order systems, less so with higher order systems. The advantage of "max rE" decoding (and also
the "in-phase" decoding) over the basic one appears more evident in terms of
stability/robustness in off-centre listening conditions (also in a relatively
low frequency domain, in these conditions), as you will experience it in this part.
Considering the rendering of a complex sound field, the
"max rE" decoding
will help the lateral separation, thus, a better interaural decorrelation in the
relatively high frequency domain, and a better preservation of the spatial
impressions.
Criterion for defining the optimal transition frequency above which the "max rE" decoding should be
applied: defining when this decoding yields globally better localization cues
than the basic one! This seems more pertinent that just applying the basic
decoding up to a frequency corresponding to an arbitrary error tolerance for the
acoustic reconstruction of ear signals.
Anyway, the
transition from one decoding to the other should not be abrupt and is rather
smooth in practice (with usual shelf-filters).
With
slightly extended area: the frequency limit decreases as the area width
increases.
The Problem of the
Spectral Balance - Discussion about the Amplitude/Energy Preservation
Criteria
The
problem:
In the low frequency domain, an
amplitude preservation criterion applies since the acoustic reconstruction is OK
for the listener. In the higher frequency domain, the wave summation at ears is
no longer fully controlled, and it is usual to consider that the contributions
are "statistically added in energy". Hence, an energy preservation criterion
applies in this bandwidth, which implies a level
compensation in this bandwidth.
The problem is that
the energy summation is not actual for each frequency: one observes a kind of comb filter effect instead (at least in the current,
very strict conditions: no diffuse field and fixed,
centred head). This comb filter effect becomes more perceptible and critical
as the level compensation is increased, which occurs when the number of loudspeakers increases (compared
with the "minimal" recommended number N=2M+2). The
level compensation is also a function of the kind of
decoding: for a given order M and a given number
N of loudspeakers, max rE decoding needs more compensation than the basic
one, and less than the in-phase one. (For more quantitative results, see the
table 3.10, chapter 3, of my thesis).
In critical situations, one feels, besides the comb filter
effect, an unpleasant spectral unbalance.
Sound
demonstration:
I'll try to put some sound
examples on this subject later...
Conclusion:
For
individual, centred listening, it's better to use the minimal, recommended
number of loudspeakers N=2M+2.
In the context of a virtual rendering (over headphones),
one could imagine an optimised process for the spectral balance, based on a
global equalisation.
Recall:  Most of time with ambisonics, all
loudspeakers are fed even for the rendering of one single sound image. With
regular loudspeaker configurations, the directional distribution of the signals
(ie the equivalent pan-pot law) is given in a
synthetic way by a single directivity pattern (a combination of spherical
harmonics up to order M) which is characteristic of
the decoding style (basic, max rE or in-phase, or, indeed, any other) and the
system order M (Cf Figure 3.14,
sec3.3, chap3 of my thesis) (click on the present figure to see a
moving source, and concentrate either on one lobe or on one loudspeaker
axis).
Most of time with ambisonics, all
loudspeakers are fed even for the rendering of one single sound image. With
regular loudspeaker configurations, the directional distribution of the signals
(ie the equivalent pan-pot law) is given in a
synthetic way by a single directivity pattern (a combination of spherical
harmonics up to order M) which is characteristic of
the decoding style (basic, max rE or in-phase, or, indeed, any other) and the
system order M (Cf Figure 3.14,
sec3.3, chap3 of my thesis) (click on the present figure to see a
moving source, and concentrate either on one lobe or on one loudspeaker
axis).
With basic decoding (the figure shows 2nd
order, basic decoding), and a little less with max rE decoding, the loudspeakers in the opposite
direction to the virtual source have a non-negligible participation (secondary
lobes of the directivity pattern). You may find it curious, but this is the
optimal feeding for a centred listening position
considering the constraints of a limited ambisonic order and a limited number of
loudspeakers! One feel that such a feeding distribution will not provide a very
robust sound imaging if the listener is placed at a distance from the centre,
and especially if he/she is close to some loudspeakers. D.Malham had proposed a modified decoding (called
"in-phase" decoding) for 1st order systems, which minimises the participation of
loudspeakers as they're at a greater distance from the virtual source. I
extended this decoding solution to any higher order (see my thesis; the 2nd
order "in-phase" decoding is also presented under the name "controlled-opposite"
by R.Furse on
his pages): their equivalent directivity patterns are all characterised
by the lack of secondary lobes (see this figure).
What happens off-centre:
Regarding the sound imaging at off-centre listening points,
two aspects have to be discussed: (1)
the directional and energetic distorsion of the
perceived contributions at this new listening point; (2) the loss of temporal
synchronism of the contributing waves at this point.  (1) - This first aspect depends only on the relative distances between each
loudspeaker and the listener (the distorsions
remain identical if we change the configuration radius R and the distance of the listener from the centre in
the same ratio): the "perceived" amplitude (convergent unfilled arrows) associated to each
loudspeaker changes in inverse ratio to its distance from the listener (in the present figure, the new listening point is
on the left at 75% of the radius R). One can
compute a local energy vector (black arrow in the figure, very small on the off-centred
point) which will partially predict the localization effect at this
point: apparent direction uE and "quality" rE(the black circle has a unitary radius, compared with this
modulus rE).
Moreover, the perceived global energy is also affected (represented by the radius of the magenta circle) compared with the one
perceived at centre (unit circle).
(1) - This first aspect depends only on the relative distances between each
loudspeaker and the listener (the distorsions
remain identical if we change the configuration radius R and the distance of the listener from the centre in
the same ratio): the "perceived" amplitude (convergent unfilled arrows) associated to each
loudspeaker changes in inverse ratio to its distance from the listener (in the present figure, the new listening point is
on the left at 75% of the radius R). One can
compute a local energy vector (black arrow in the figure, very small on the off-centred
point) which will partially predict the localization effect at this
point: apparent direction uE and "quality" rE(the black circle has a unitary radius, compared with this
modulus rE).
Moreover, the perceived global energy is also affected (represented by the radius of the magenta circle) compared with the one
perceived at centre (unit circle).
 (2) - The second aspect introduces the problem of
the precedence effect (also known as "Haas effect"
with speech signals, and also referred as the "law of the first wave front") (Cf eg Blauert: "Spatial Hearing"). Very basically, it
says that the listener tends to localise the sound source in the direction of
the earliest wave front. But things are actually not so simple. The localisation
effect depends on several parameters: their relative energetic weight (discussed above), the sharpness of the
original signal, and the time scale of the wave front succession (thus, unlike the energetic/directional distorsion
previously discussed, this effect depends also on the
absolute distance). The effects of these last two parameters are
illustrated with these sound examples (to be listened
over headphones!). This is the case of a 1st order, basic rendering, with a
virtual source placed at -90° (right hand), and a listening position at 10% of
the loudspeaker radius R on the left half axis (see
the figure in the margin). In terms of energy vector distorsion, the "quality"
rE =0.65 is only a
bit less than at centre (where rE =0.67). We move from a little radius (1m) to a
huge one (12m).
(2) - The second aspect introduces the problem of
the precedence effect (also known as "Haas effect"
with speech signals, and also referred as the "law of the first wave front") (Cf eg Blauert: "Spatial Hearing"). Very basically, it
says that the listener tends to localise the sound source in the direction of
the earliest wave front. But things are actually not so simple. The localisation
effect depends on several parameters: their relative energetic weight (discussed above), the sharpness of the
original signal, and the time scale of the wave front succession (thus, unlike the energetic/directional distorsion
previously discussed, this effect depends also on the
absolute distance). The effects of these last two parameters are
illustrated with these sound examples (to be listened
over headphones!). This is the case of a 1st order, basic rendering, with a
virtual source placed at -90° (right hand), and a listening position at 10% of
the loudspeaker radius R on the left half axis (see
the figure in the margin). In terms of energy vector distorsion, the "quality"
rE =0.65 is only a
bit less than at centre (where rE =0.67). We move from a little radius (1m) to a
huge one (12m).
| Configuration radius | R=1m | R=2m | R=3m | R=6m | R=9m | R=12m | Concatenation (1|2|3| 6|9|12m) |
| 10ms bell shaped burst | 10ms R1m 10% | 10ms R2m 10% | 10ms R3m 10% | 10ms R6m 10% | 10ms R9m 10% | 10ms R12m 10% | 10ms 10% |
| 30ms bell shaped burst | 30ms R1m 10% | 30ms R2m 10% | 30ms R3m 10% | 30ms R6m 10% | 30ms R9m 10% | 30ms R12m 10% | 30ms 10% |
| 100ms bell shaped burst | 100ms R1m 10% | 100ms R2m 10% | 100ms R3m 10% | 100ms R6m 10% | 100ms R9m 10% | 100ms R12m 10% | 100ms 10% |
| maximum time delay (path length difference between earliest and latest wave fronts) |
0.59ms (20cm) | 1.18ms (40cm) | 1.77ms (60cm) | 3.53ms (1.2m) | 5.3ms (1.8m) | 7.06ms (2.4m) |
Because we're unable to integrate these latter aspects in a synthetic prediction tool, we will use the only energy vector for the visualization of the supposed localisation effect. And that's not a bad thing, since we can compare a local (off-centre) energy vector with the reference one (at centre): off-centre, the earliest wave fronts are also those whose amplitude have "increased" (for the listener), thus the possible precedence effect acts on the localisation in the same direction as the energy vector is distorded towards.
Now, let's have a little more fun with the next sound demos!...
The scenario (for the listening test):
I have chosen to present the case of a moving single
source, drawing a regular, circular trajectory around the listener. There are
two reasons for this choice. First, I was unable to create a complex, realistic
ambisonic sound field at any order (it would
require using an efficient/realistic room effect processor with a true ambisonic
encoding). Second, this is more convenient for appreciating the
directional distorsion of the sound image, and its regularity or its
fluctuations as a function of the originally expected azimuth.
Here, the sound file is a 10.6 s extract of a Chopin Walz played on a piano (Walz in A flat major, as played by Jean-Marc
Luisada). You could imagine you're walzing in
a ball-room, turning and turning, but the fact is that you're staying static...
Let's consider instead a less usual but more convenient image: you're in the
middle of a "merry-go-round" ("un manège" in french) and the sound is coming
from a moving wood horse (played rather by a
loudspeaker than by a piano!) ...  In this
situation, you're hearing something like that
(please configure your player to play in
loop). The source draws exactly two circles around the listener, starting
on the front and beginning to move left (anti-clock wise). Click here to vizualize the
trajectory (click on the appearing image
if needed) (the green o
represents the source position and the arrow placed at the centre gives the
perceived direction). It is possible that you fail to feel the sound
image in front of you when it is supposed to be there. But try to imagine a
circular trajectory around you (in the horizontal plane), and train yourself to
feel that: it will be useful for the next listening tests.
In this
situation, you're hearing something like that
(please configure your player to play in
loop). The source draws exactly two circles around the listener, starting
on the front and beginning to move left (anti-clock wise). Click here to vizualize the
trajectory (click on the appearing image
if needed) (the green o
represents the source position and the arrow placed at the centre gives the
perceived direction). It is possible that you fail to feel the sound
image in front of you when it is supposed to be there. But try to imagine a
circular trajectory around you (in the horizontal plane), and train yourself to
feel that: it will be useful for the next listening tests.
This is the situation that our ambisonic systems will
try to reproduce: a virtual ambisonic microphone placed at the centre encodes
the sound source (the incident wave is supposed to be plane), and various
decoding are applied. 1st, 2nd and 3rd order systems are illustrated here. The
loudspeaker configuration is the same for any rendering: a regular octohedral
configuration (horizontal rendering).
The rendering is
simulated for 4 listening positions distributed on the left half axis, the
distance from the centre being 0% (centred
pos., shown with 50% and 75% pos.), 25%, 50% and 75% of the loudspeaker
configuration radius.
|
|
1st order | 2nd order | 3rd order |
| Basic decoding | r:25%|r:50%|r:75% | r:25%|r:50%|r:75% | r:25%|r:50%|r:75% |
| Max rE decoding | r:25%|r:50%|r:75% | r:25%|r:50%|r:75% | r:25%|r:50%|r:75% |
| In-phase decoding | r:25%|r:50%|r:75% | r:25%|r:50%|r:75% | r:25%|r:50%|r:75% |
Now you'll confront these movies with the corresponding listening experiences (listen over headphones!)... For these sound simulations, the configuration radius is fixed to R=2 meters.
About the MP3
encoding/decoding:
How to play them? Players and
encoders can be found as freeware or shareware from this site.
The signal degradation.
This files have been encoded at 128 kbits/s. There are many other kinds of sound
(than piano) which are much more critical for this encoding, so the degradation
could be much more annoying than there. Nevertheless, if you play (always over
headphones!) the files loud enough, you will hear a little babbling in addition
to the piano sound... Try to imagine it's happening outside and forget it:
concentrate only on the piano! Anyway, I've verified that the MP3 encoding
doesn't really affect the directional effect, compared to the original
(uncompressed) wav versions.
The sampling frequency is 32 kHz. Each file is about 10,6 s
and weights 167 Ko (versus 1331 Ko for the uncompressed wav file).
| Single
source 0%|25%|50%|75% |
1st order | 2nd order | 3rd order |
| Basic decoding | r:0%|r:25%|r:50%|r:75% | r:0%|r:25%|r:50%|r:75% | r:0%|r:25%|r:50%|r:75% |
| Max rE decoding | r:0%|r:25%|r:50%|r:75% | r:0%|r:25%|r:50%|r:75% | r:0%|r:25%|r:50%|r:75% |
| In-phase decoding | r:0%|r:25%|r:50%|r:75% | r:0%|r:25%|r:50%|r:75% | r:0%|r:25%|r:50%|r:75% |
Train yourself with the reference file first (single source r=0%) if you have not already done so, in order to really imagine that the source is drawing a circular (anti-clock wise), horizontal trajectory around you.
How to synchronize
sounds and movies:
The simplest, but less satisfying method is: while playing
your sound file (table 8) in a loop, open the associated movie (table 7) and
start it when you hear that the sound file rewinds. I've adjusted the frame rate
correctly (2 movie loops = sound file duration).
An other and more
elegant method: use the great and easy shareware called "VideoMach" (http://www.gromada.com) or an equivalent software; open
the movie twice and the associated sound file once; File|Define Output, choose
"Video and Audio (same file)" and choose a filename.avi; in the same box:
Video|Format Options, choose preferably MicrosoftVideo1; close the boxes (OK);
then File|Start Processing. This produces a rather big file (because the sound
is then uncompressed, that's why I can't put this on this page) but with sound
and images automatically synchronized.
Now compare one sound simulation with the associated
movie (synchronize them if possible): concentrate either on the directional
effect (energy vector, black arrow), or on the energy fluctuation (magenta circle). Perhaps you will
agree with my own feeling: I find that the listening experience corroborates
very well the graphical visualization (and vice-versa)!
At a critical
listening position, the sound image evolution is always smoother with the
in-phase decoding than with others (especially basic), but higher order max rE rendering is quite
robust too, and offers a more precise imaging.
Conclusions
Basic decoding is (very) under-optimal
for (very) off-centred listening positions. In-phase decoding is the more robust
decoding (smooth and continuous evolution of sound imaging) when the listening
area extends to the loudspeaker periphery. The sound imaging becomes globally
more precise and robust as the system order M
increases.
For a given order M, there's a limit distance from the centre below which
the max rE decoding
is more suitable than the in-phase one, and above which it's the contrary. This
distance probably increases (for a given radius R)
as the order M increases.
For a given order M and a given limit distance, an optimal decoding could
be an interpolation between max rE and in-phase decoding.
Further listening tests should be
carried through for more quantitative results and conclusions.
The present sound examples have featured
decoding solutions applied on the full frequency band. But the optimal decoder
may use several decoding solutions distributed over the
frequency range (with a "shelf-filtering"). I've
proposed (Figure 3.4, chap.3 of my thesis, see
also the powerpoint
presentation) that in some cases, the main three kinds of decoding
could be involved at the same time: the "basic" one in a (very) low frequency
domain, the "max rE"
one in the intermediate (low/middle/high? frequency) band and the "in-phase" one
in the middle/high frequency band.

Lastly, we can expect that another
problem will appear with complex sound fields:
because of the level unbalance occuring off-centre, it's likely that the sound
masking (of one side of the sound panorama by the other one) will lead to a loss of spatial informations and impressions (including
envelopment).
Off-Centre, Low
Frequency Localization - Prediction by the Energy Vector
I have shown (see my PhD thesis)
that the energy vector should be a low-frequency
localisation predictor at an off-centred listening position, the low
frequency domain being such that the detection is based on interaural phase
delay and that the phase coherency of the loudspeaker contributions is no longer
observed at the listening point (so, above a frequency in inverse ratio to the
distance from the centre).
Maybe I'll build some
experiments to let you hear that?...
If my head were acoustically transparent ...
-
Centred Head, HF Localization Only Based on ITD Detection -
Prediction by the Energy Vector
I
have given a partial proof (see my PhD thesis, or
above) that the energy vector
can predict the (HF) localization effect, assuming the head is centred, and
considering only the HF ITD detection (interaural group delay). Mathematically, this proof works the best with the
hypothesis of an acoustically transparent head. In the real life, one must take
the head diffraction effect into account, of course. This implies an ILD
(Interaural Level Difference), which is an other important cue for the detection
of lateral events in the HF domain. It is clear that the closer the energy
vector modulus is to 1 (ie the more the energy contributions are concentrated
in the same direction), the more significant ILD is for lateral virtual
sources, but there's no simple prediction law.
Anyway,
it's difficult to verify perceptually how the group
delay detection itself helps for the localization. I'm curious to know how I
could detect directional events if my head were acoustically transparent...
there wouldn't be any diffraction, thus neither ILD.
First published: 2000/12/20 - Last slightly modified: 2004/01/28
{kind=link}